Prefetchers on Commercial CPUs
AMD
AMD family 19h processors implement data prefetch logic for its L1 data cache and L2 cache. In general, the L1 data prefetchers fetch lines into both the L1 data cache and the L2 cache, while the L2 data prefetchers fetch lines into the L2 cache. (意思是L1分流,L2不分流)
The following prefetchers are included:
- L1 Stream: Uses history of memory access patterns to fetch additional sequential lines in ascending or descending order
- L1 Stride: Uses memory access history of individual instructions to fetch additional lines when each access is a constant distance from the previous.
- L1 Region: Uses memory access history to fetch additional lines when the data access for a given instruction tends to be followed by a consistent pattern of other accesses within a localized region.
- L2 Stream: Uses history of memory access patterns to fetch additional sequential lines in ascending or descending order.
- L2 Up/Down: Uses memory access history to determine whether to fetch the next or previous line for all memory accesses.
Software optimization guide for amd epyc 7003 processors.
Intel
Intel使用了哪些prefetcher
Disclosure of H/W prefetcher control on some Intel processors
| Prefetcher | Bit# in MSR 0x1A4 | Description |
|---|---|---|
| L2 hardware prefetcher | 0 | Fetches additional lines of code or data into the L2 cache |
| L2 adjacent cache line prefetcher | 1 | Fetches the cache line that comprises a cache line pair (128 bytes) |
| DCU prefetcher | 2 | Fetches the next cache line into L1-D cache |
| DCU IP prefetcher | 3 | Uses sequential load history (based on Instruction Pointer of previous loads) to determine whether to prefetch additional lines |
| If any of the above bits are set to 1 on a core, then that particular prefetcher on that core is disabled. Clearing that bit (setting it to 0) will enable the corresponding prefetcher. |
- The algorithms found in the L1 cache hardware are the Data Cache Unit (DCU) Prefetcher (INTEL, 2019) and the DCU IP Prefetcher (INTEL, 2019). The DCU Prefetcher, also known as the streaming prefetcher, is triggered by an ascending access to very recently loaded data. The processor assumes that this access is part of a streaming algorithm and automatically fetches the next line. The DCU IP Prefetcher keeps track of individual load instructions (based on their instruction pointer value). If a load instruction is detected to have a regular stride, then a prefetch is sent to the next address which is the sum of the current address and the stride.
- The L2 Hardware Prefetcher (INTEL, 2019) and the L2 Adjacent Cache Prefetcher (INTEL, 2019) are the prefetcher algorithms found in the real machine L2 cache. The L2 Hardware Prefetcher monitors read requests from the L1 cache for ascending and descending sequences of addresses. Monitored read requests include L1 data cache requests initiated by load and store operations and also by the L1 prefetchers, and L1 instruction cache requests for code fetch. When a forward or backward stream of requests is detected, the anticipated cache lines are prefetched. This prefetcher may issue two prefetch requests on every L2 lookup and run up to 20 lines ahead of the load request. The L2 Adjacent Cache Prefetcher fetches two 64-byte cache lines into a 128-byte sector instead of only one, regardless of whether the additional cache line has been requested or not.


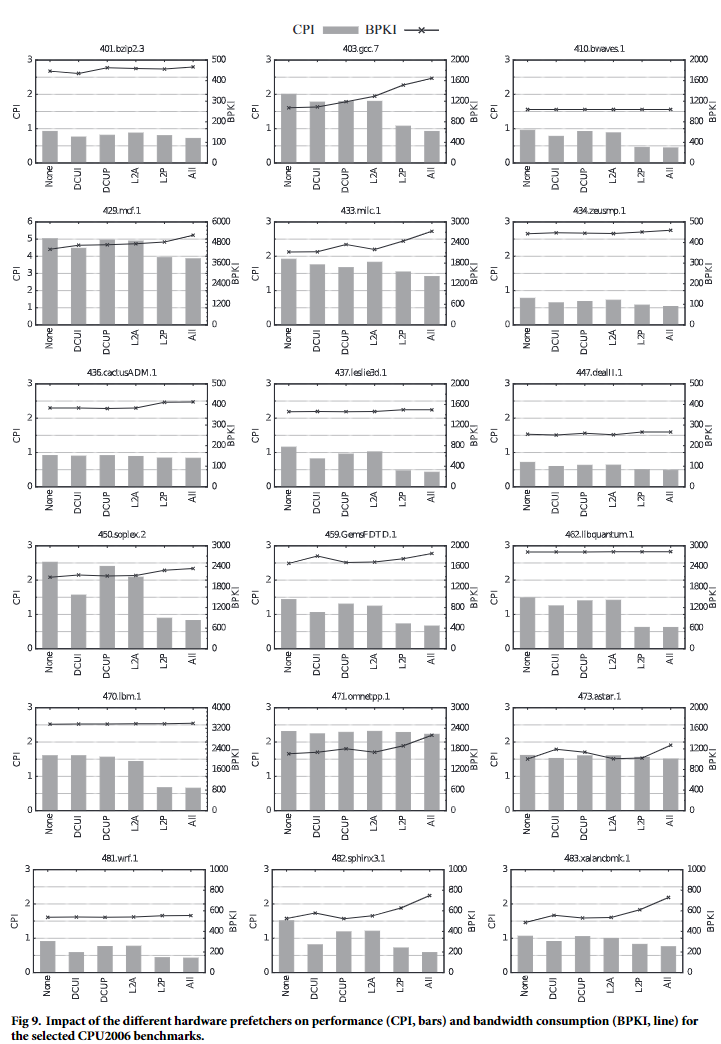
Prefetcher Performance
Performance: L2P > DCUI > DCUP > L2A
为什么streamer会性能最好,难道L2A是stride prefetcher?
Stream Prefetcher (L2/LLC)
- Train stream using BBL transactions
- Read streams and send prefetch requests to L2Q
16 instruction streams, 32 data streams
Each stream is for a 4K page and is core specific
Streams are replaced using round robin when there's no empty stream
| Request is Demand Type | CAM Match | Request got L2 Hit | Action |
|---|---|---|---|
| 0 | 0 | x | Do nothing |
| 1 | 0 | 1 | Do nothing |
| 1 | 0 | 0 | Stream Creation |
| x | 1 | x | Stream Update |
最前面表示cache line
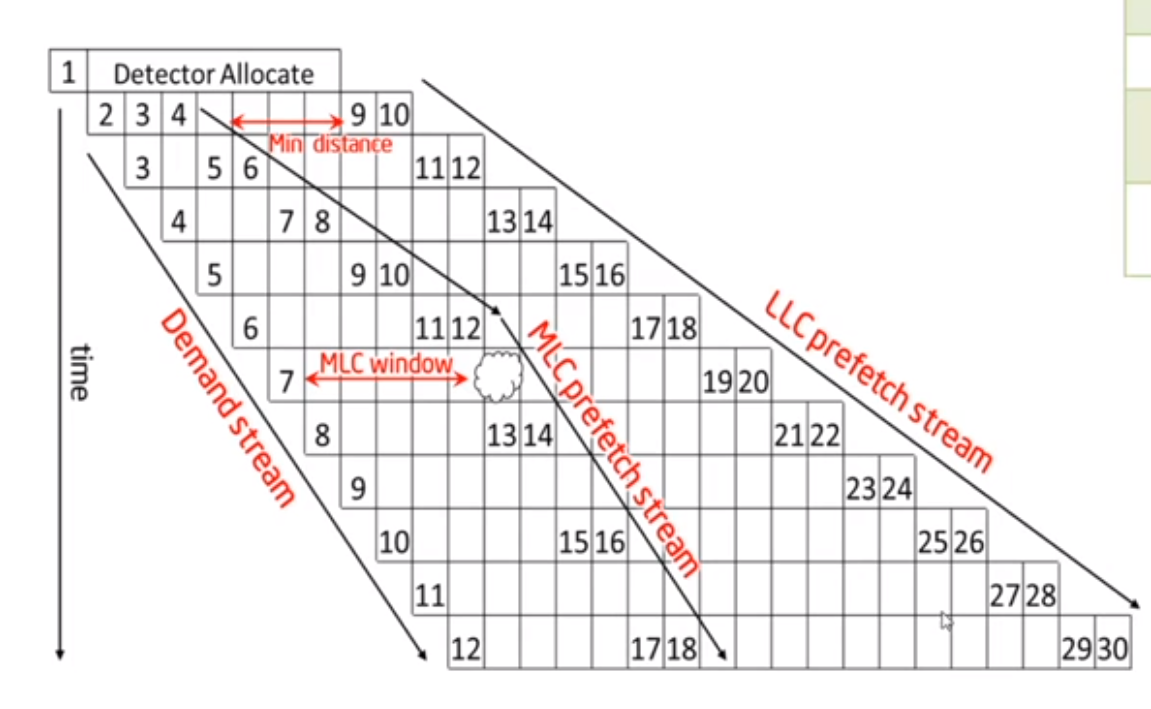

- (a) Demands hitting the far fall back window twice in a role will put the stream in searching state and set num_prefetch_pending = 0
- (b) Increament the LLC num_prefetch_pending by a creg value
- (c) Increament the L2/LLC num_prefetch_pendings by creg values (common case)
- (d) Increment the L2/LLC num_prefetch_pendings by skip_ahead creg values.
A Stream Lift Cycle
A stream has 4 states: Searching, Forward, Backward, Done
- Start with Searching (ex. stream allocate)
- Move from Searching to Forward/Backward if there's enough demands to determine the direction
- Ideally, stay in Forward/Backward until the L2 homeline reaches page-end/page-begin, Then move to Done.
- In Done state, the stream can either move back to Searching (cache miss) or be replaced for another 4K page
stream state machine
D-Side State Machine
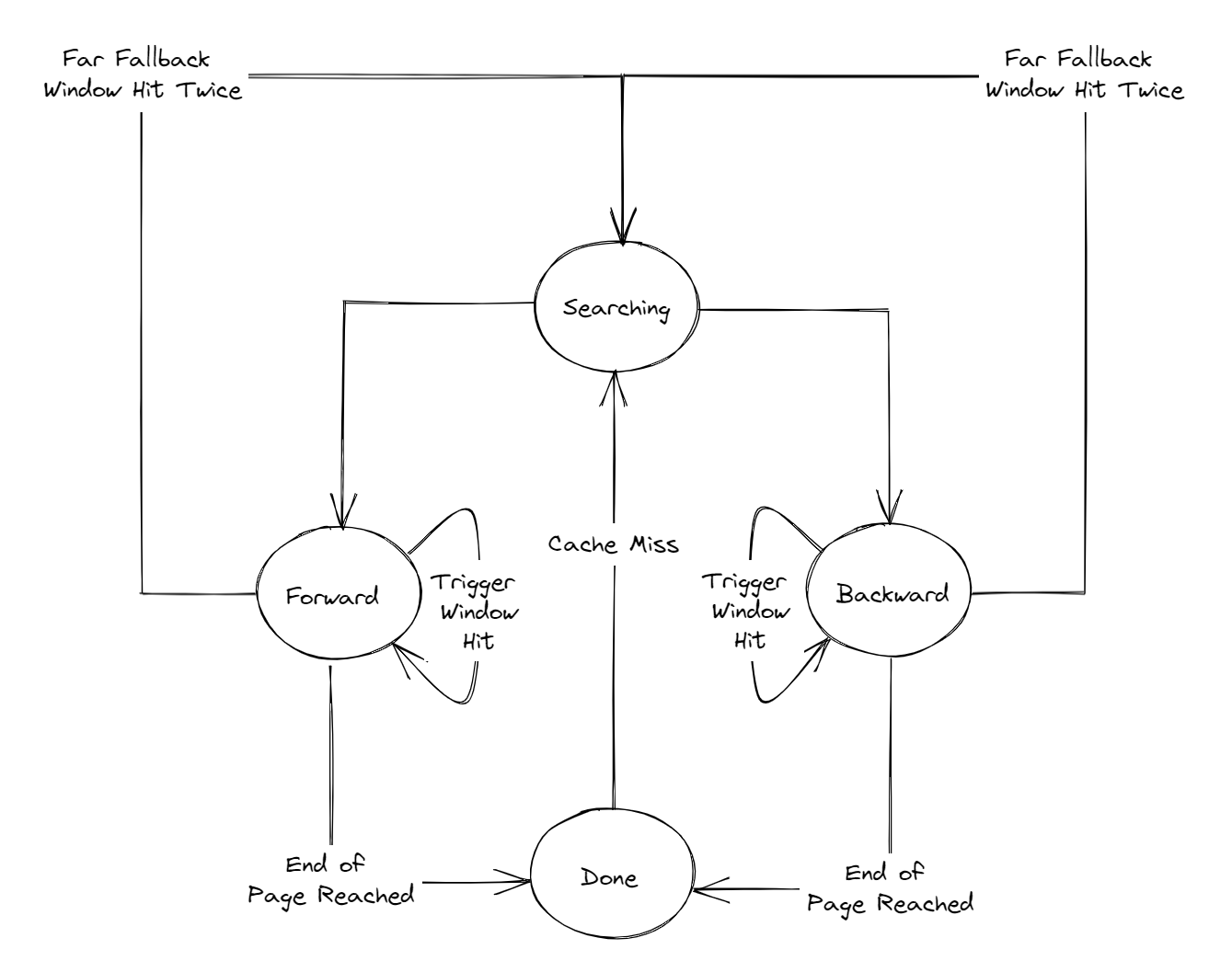
- New stream create (eb_allocate_new_ms58h)
- page begin kickstart: Forward
- page end kickstart: Backward
- Otherwise: Searching
- Searching
- within_initwin_fwd: Forward
- Within_initwin_bck: Backward
- Otherise: Searching
- Done
- cache miss: Searching
- Otherwise: Done
- Forward/Backward
- within_new_skipahead_ms58h
- increment perf_pending
- Move home lines
- Stable_strm_prefpending_ms58h
- increment pref_pending
- Within_trig_win_ms58h
- increment pref_pending
- Move home lines
- Within_fallback_ms58h
- Increment pref_pending (LLC only)
- Move home lines
- If detects reverse direction twice (Within_far_fallback_ms58h) and cache miss
- Searching
- within_new_skipahead_ms58h
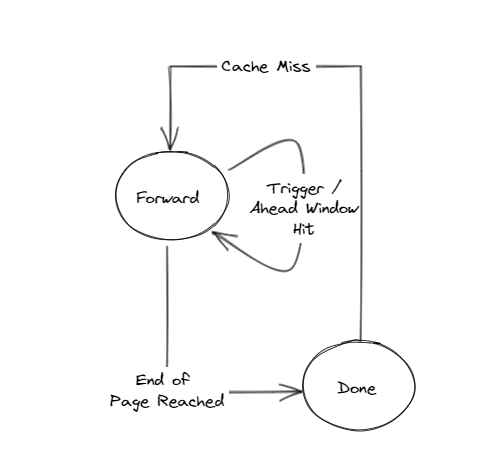
I-Side State Machine
- The only states are Forward and Done (no Searching, no Backward).
- Kick start to forward state during stream allocate, no searching state.
- L2 prefetch only (no LLC prefetch)
- Never overwrite L2 prefetch pending with a smaller value
- When hitting the fallback windows, no update to the stream (also no update to pref_pending).
Stream's Key Fields
- Page address[51:12]
- State // Searching/Forward/Backward/Done
- L2 home offset[11:6] (page offset 减去 cache line offset)
- L2 prefetch pending // number of L2 prefetches pending to be sent out
- LLC home offset[11:6]
- LLC prefetch pending // number of LLC prefetches pending to be sent out
- AMP last offset[11:6]
- AMP delta1 // index to prediction table (SPT0, SPT1)
- AMP delta2 // index to prediction table (SPT1)
- AMP new page
Stream Prefetcher: LLC
- The LLC home line maintains a min/max distance from the L2 prefetch home line (max distance is disabled).
- The LLC home line typically finishes (ex. end of page) before the L2 home line. The stream moves to the Done state when the L2 home line finishes
- LLC prefetch is only for data and not instruction (I-side).
- Implementing I-side LLC would require an entirely new windowing scheme.
- I-side doesn't typically need to prefetch as far ahead anyway
- No plan to implement I-side LLC at this point
Stream Prefetcher: SendStream (Send Prefetch Requests to L2Q)
Processes
- Read the 48 streams one-by-one using the round robin method
- If the stream has L2/LLC prefetch pending number != 0
- Decrement the prefetch pending number by 1
- Increment the L2/LLC home line (prefetch offset) by 1 forward state
- Decrement the L2/LLC home line (prefetch offset) by 1 backward state
- Send out 1 prefetch with address =
- Move on to the next stream
- For each stream, ping-pong between L2/LLC prefetch
- For Forward state, set the stream state = DONE whe the L2 home line reaches the end of the 4K page
- For Backward state, set the stream state = DONE when the L2 home line reaches the begining of the 4K page.
Bitmap Filter (For each stream)
- Before a prefetch request is sent to L2Q, check again
- Update the bitmap filter bit corresponding the prefetch addres
L2Q credit
- only send prefetch request to L2Q when there's L2Q credit available (eb_pref_req_credit_avail_mnnnh)
Prefetch Accelation and Throttling

Prefetcher Blocking

Intel Stream Prefetcher Reverse Engineering
Structure
- A table of stream entries tagged by a page number. Each entry contains the last fetched line in the page, a direction state, and a prefetcher confidence state. The last fetched line (L) is the last prefetch candidate or the last request when lacking such a candidate.
- The prefetch candidate logic block takes as an input the miss from the L1 cache and the stream entry for the same page. It uses the stream direction state and last fetched line to suggest prefetch candidates and update the stream entry.
- The prefetch confidence logic block computes and updates the confidence prefetcher for this stream based on requests made and whether they fit the stream.
- The prefetch arbitration logic uses the confidence and candidates from all prefetchers to pick which to issue.
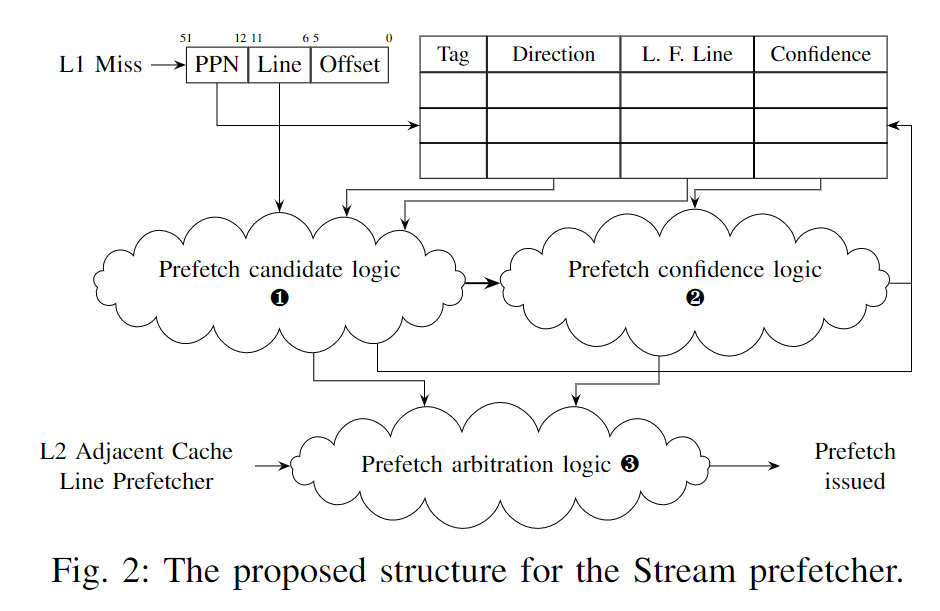
The Stream prefetcher treats in a special way streams that first access a page in its first or last two lines (如果access了一个page中的前两个或者后两个line 会触发prefetch).
Otherwise, if confident enough, it prefetches a pair of consecutive lines starting on the last fetched line or the current line, whichever is furthest along the direction of the stream. (有两个起始地点)
Accesses 32 or more lines away from the last fetched line are treated differently. (current line和last fetched line不能差距太远)
Prefetches issued will safely wrap around page limits, which may issue pointless prefetches but causes no potentially dangerous prefetches across page limits.
The prefetcher seems to output a confidence metric used to decide whether to prefetch, but suppressed prefetches may update the prefetcher state. Lastly, the prefetcher is reluctant to start streams too close to the page end.
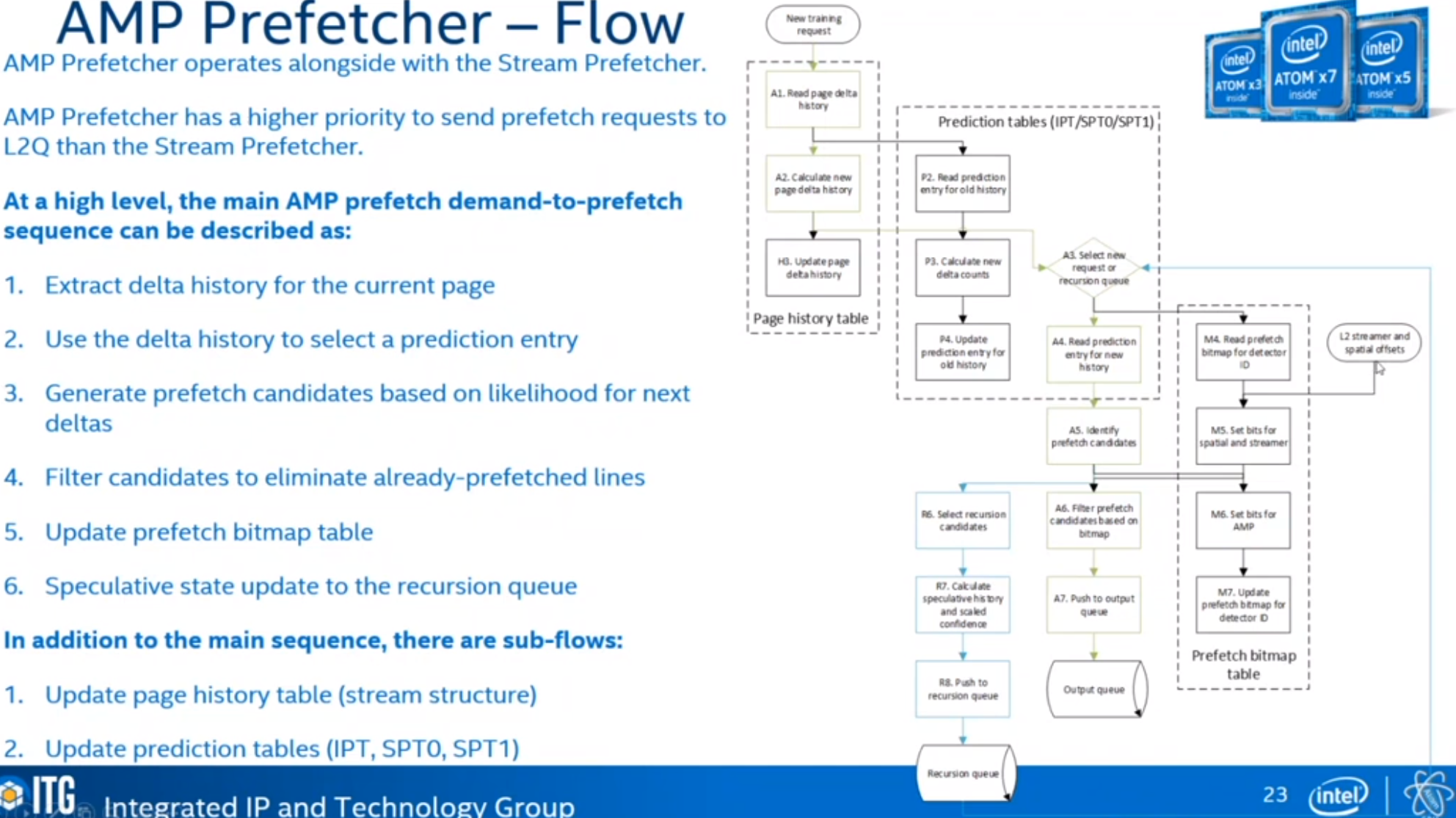
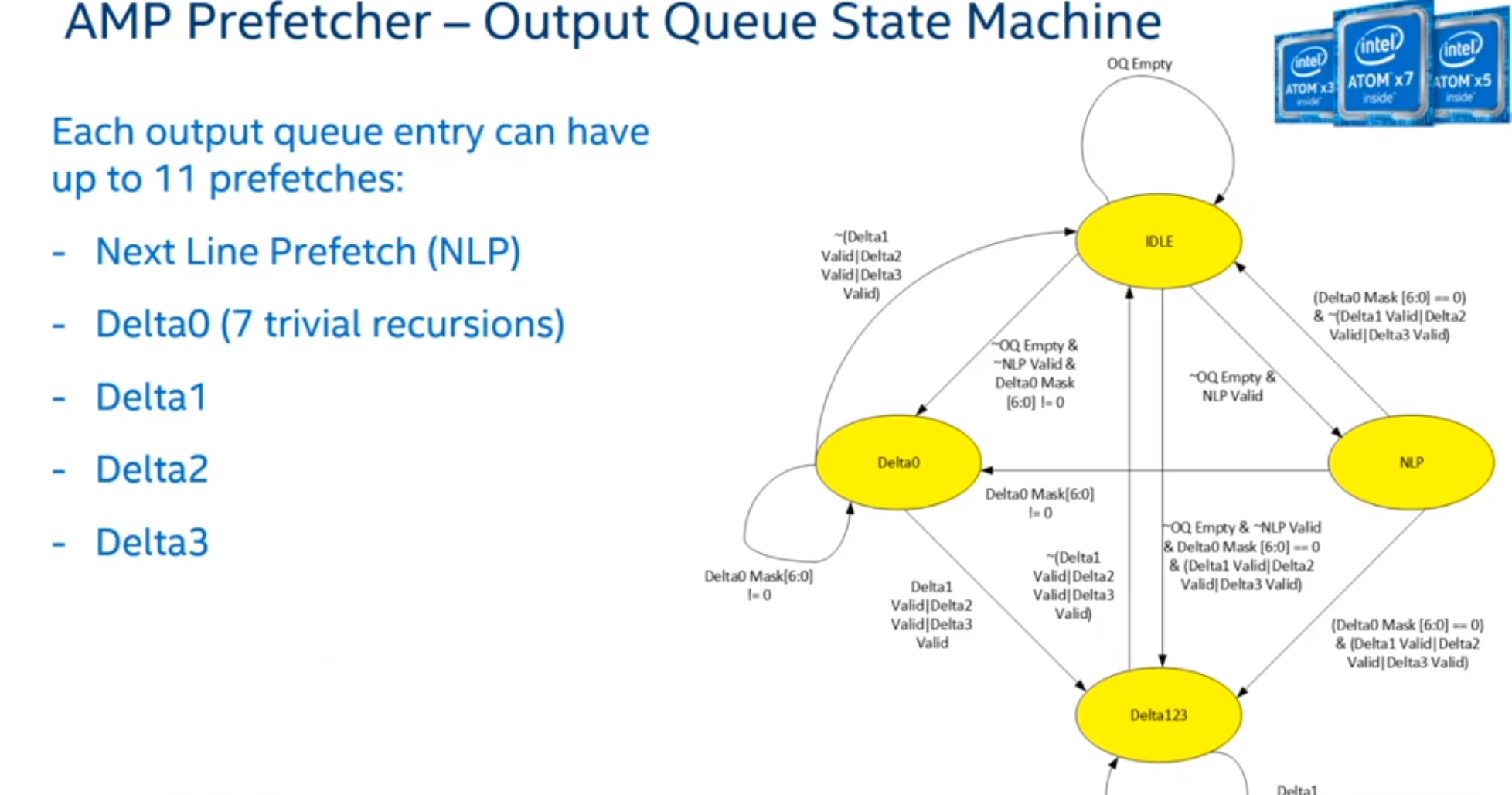
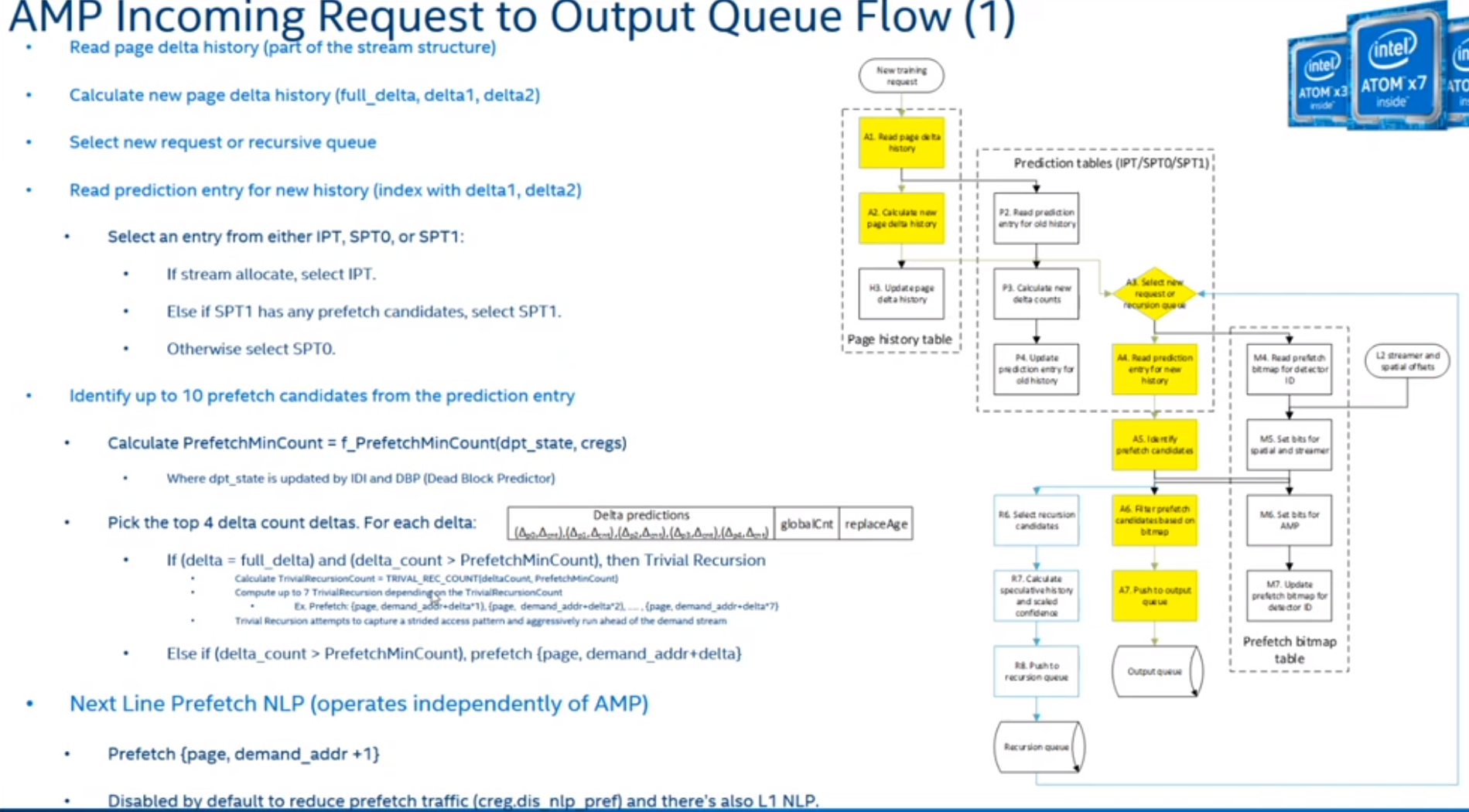
AMP Prefetcher
Glossary
- DetectorID(aka Stream_Tag): Page frame address, i.e. addr[51:12]
- Offset: address offset from the page address base, i.e. addr[11:6]
- Full_Delta: (New_offset - last_offset) (6 bit value)
- Delta1: Bucket1(Full_Delta)
- Delta2: Bucket2(Delta1)
- Page History Table: Streamer entry
- IPT: Initial Prediction Table
- SPT: Sequence Prediction Table
- PrefethMinCount: Confidence threshold
Data Structure

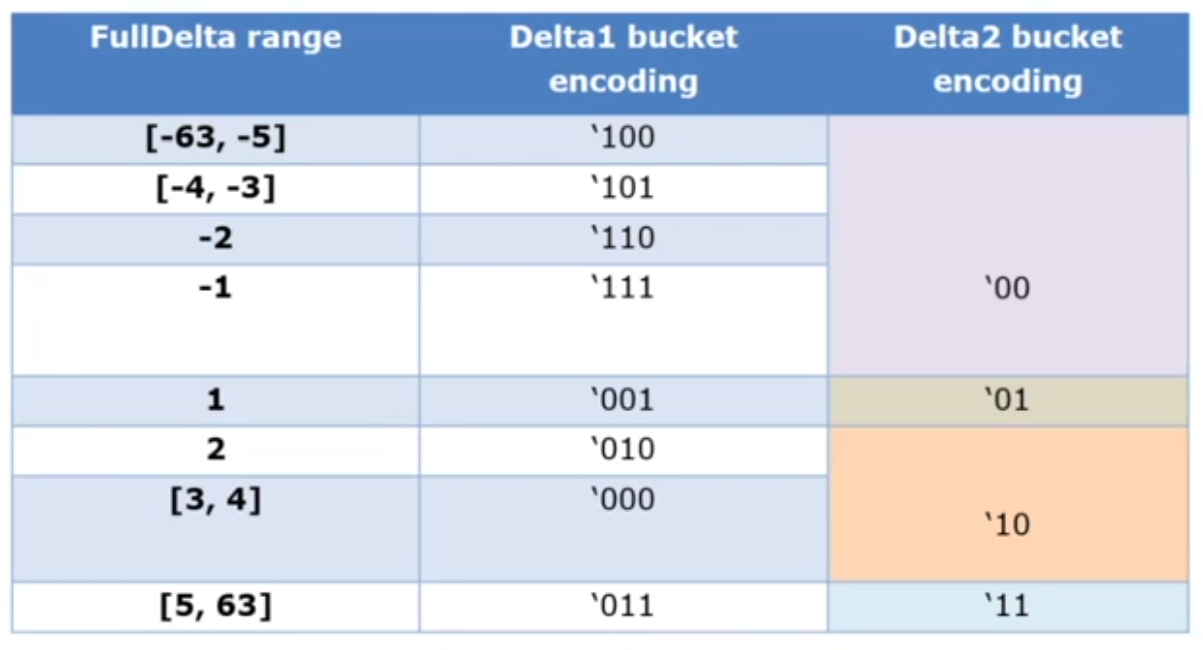
Delta Bucket Encoding (Index Into SPT0/SPT1)
- FullDelta = current_offset - last_offset
- SPT0 table has 8-entry
- indexed by Delta1
- SPT1 table has 32-entry
- Indexed by
Steps
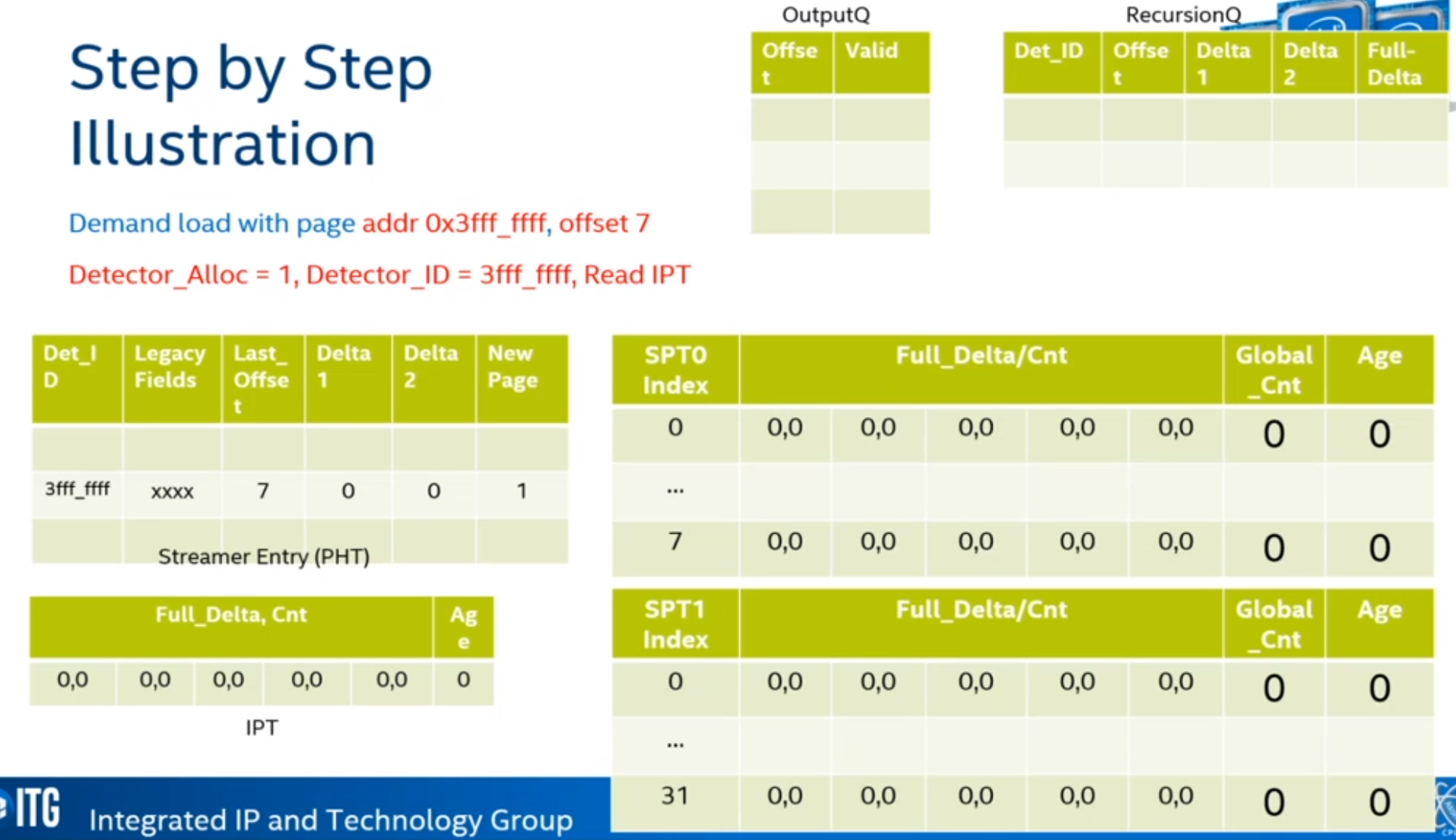

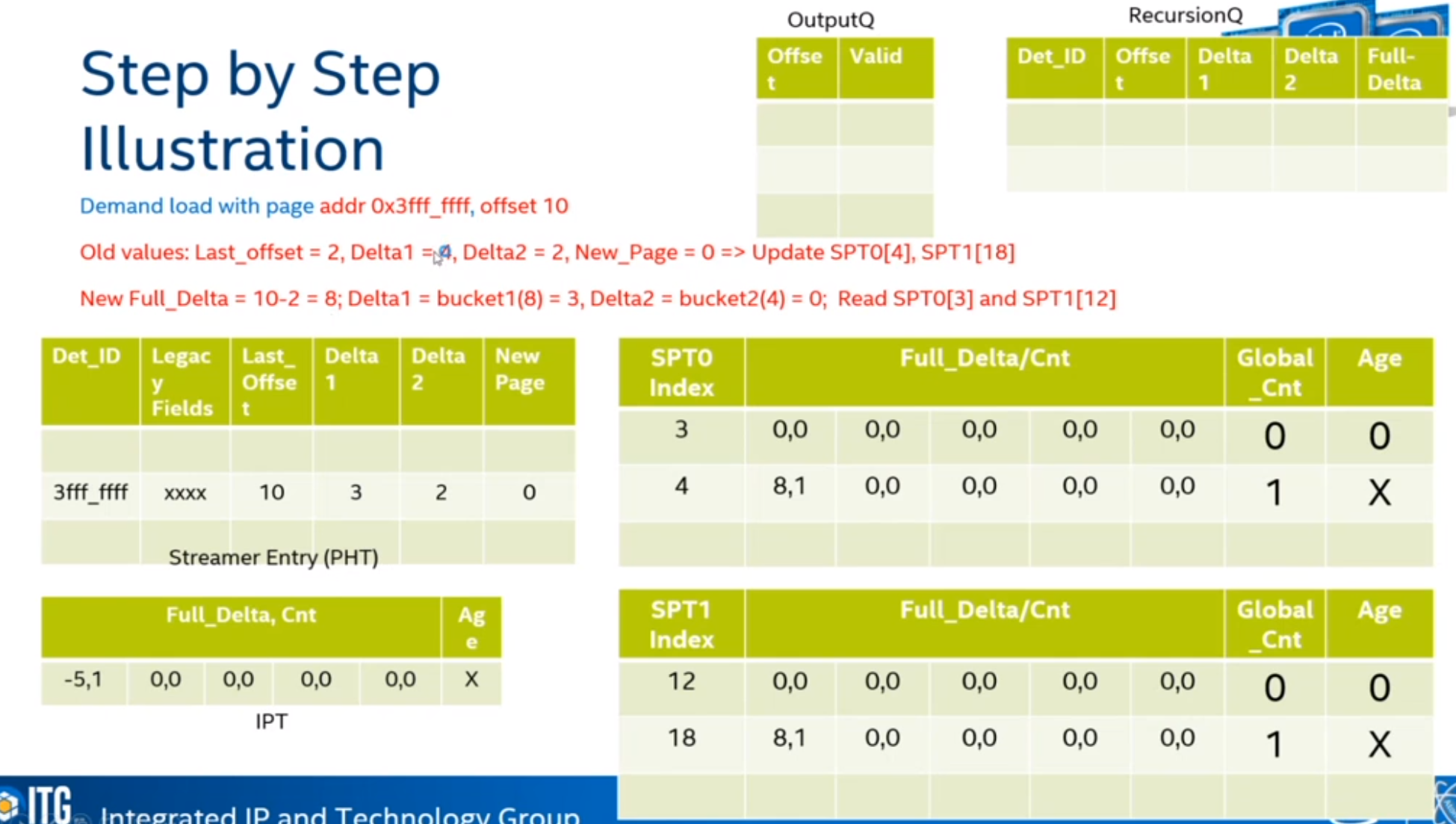
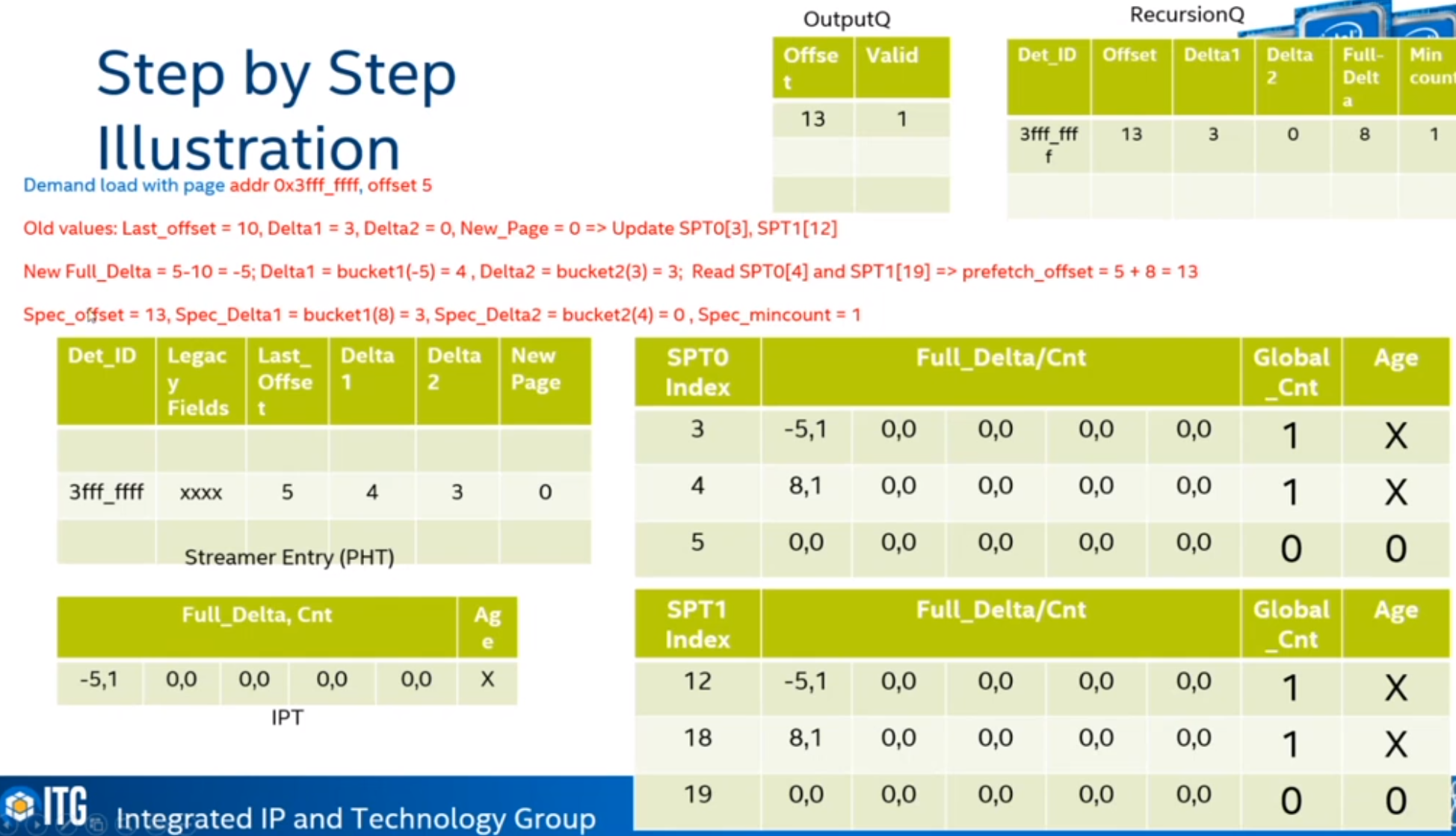
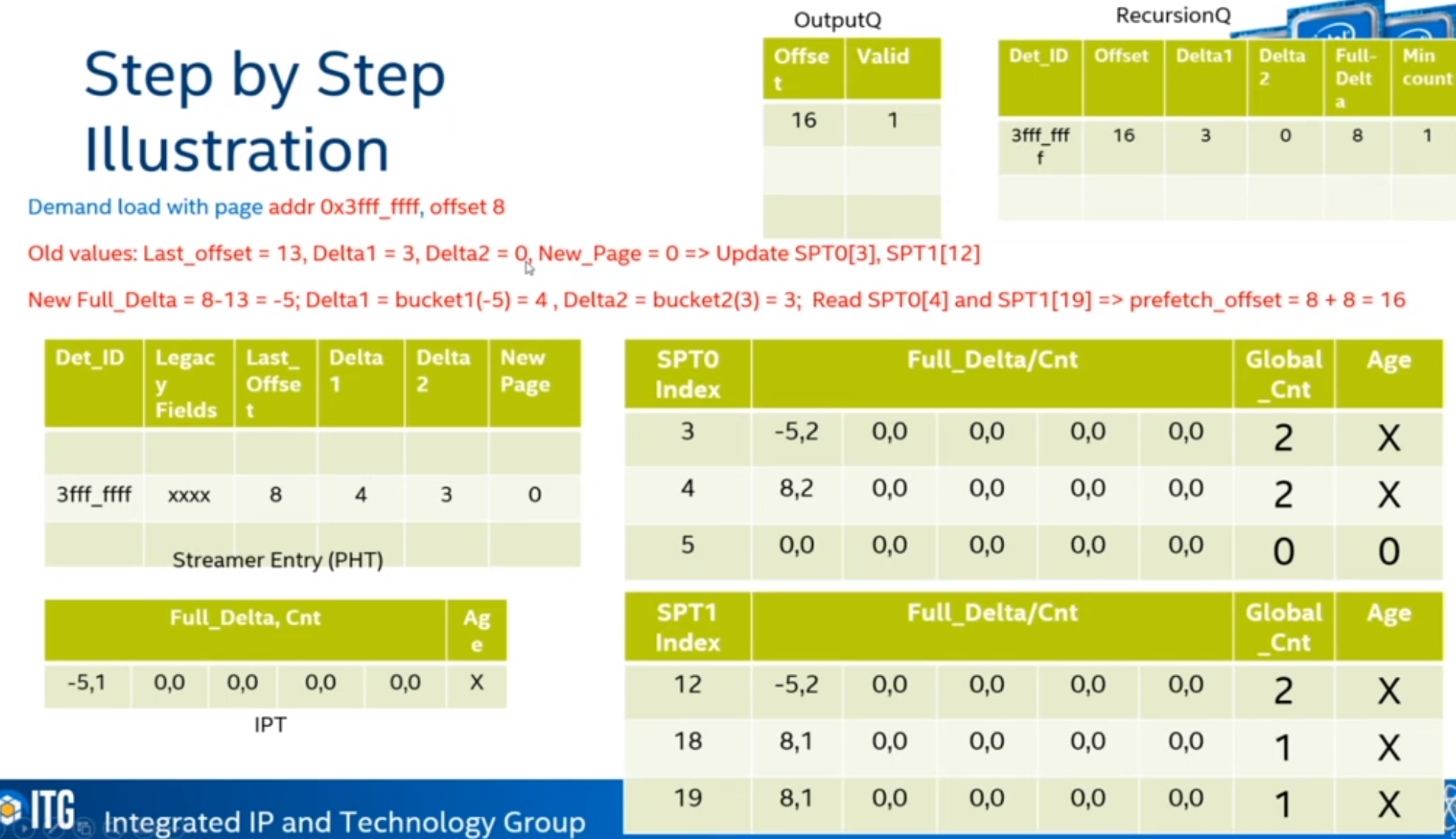
ARM
APPLE
- DMP
augury.pdf
X3
The X3 features a dozen prefetch engines.
One new engine looks for sequences of indirect loads while the other seeks three-dimensional(spatial) patterns.