Temporal Prefetcher
0. Temporal Pattern
- Definition: a sequence of addresses that favor being accessed together and in the same order (e.g., if we observe {A; B; C; D} then it is likely for {B; C; D} to follow {A} in the future).
- Source: loops; pointer-based structures are traversed in program
- Shortcomings
- (准确率低)Temporal prefetching techniques exhibit low accuracy as they do not know where streams end.
- (无法避免compulsory miss)As temporal prefetchers rely on address repetition, they are unable to prevent compulsory misses (unobserved misses) from happening
- (存储开销高)As temporal prefetchers require to store the correlation between addresses, they usually impose large storage overhead (tens of megabytes) that cannot be accommodated on-the-chip next to the cores.

1. Category 1: GHB-Based
1.1. STMS (Sampled Temporal Memory Streaming)
在global access stream上记录address correlation (pairs of correlated address, 比如访问了A之后接下去会访问B)。然后根据address correlation来issue prefetch requests。
STMS通过一个FIFO buffer来记录global stream的address correlation。比如一个访问序列A,B,C,D,E,这些被记录到FIFO buffer。接下来如果遇到一个A的访问,则STMS认为接下来可能会访问B
a. Structure
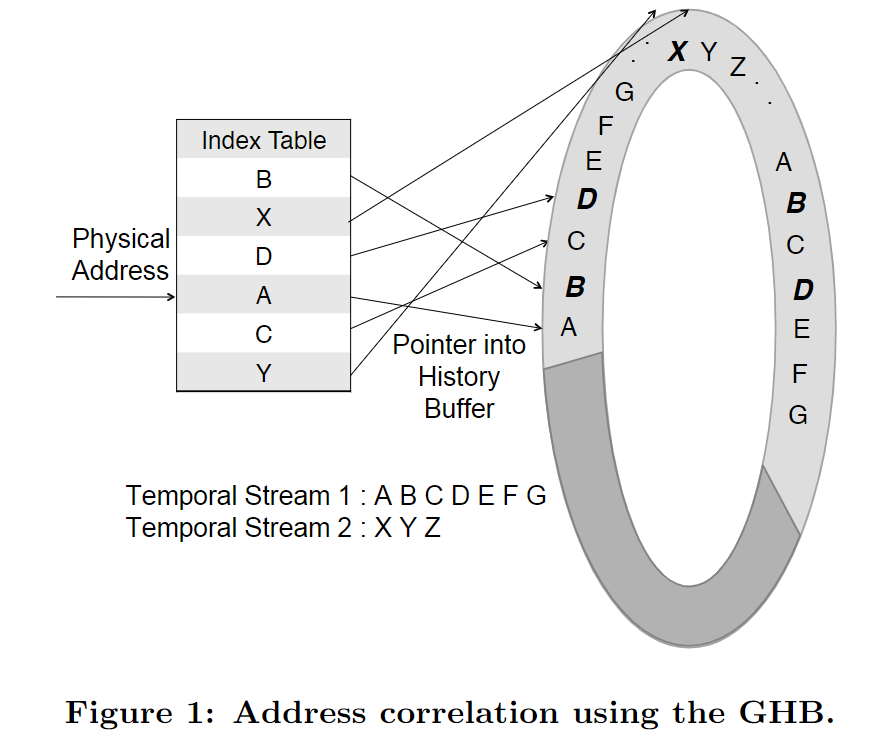
- History Table: a circular FIFO buffer记录访问的addr
- 每次cache miss发生,会将miss数据放到FIFO buffer的末尾
- Index Table: set-associative structure, stores a pointer for every observed miss addr to its last occurrence in the History Table
b. Process
- Cache miss发生的时候,prefetcher先查找index table, 找到miss addr,获取对应到history table的指针
- prefetcher找到history table中的位置,然后开始为后续地址发起prefetch请求
c. Comments
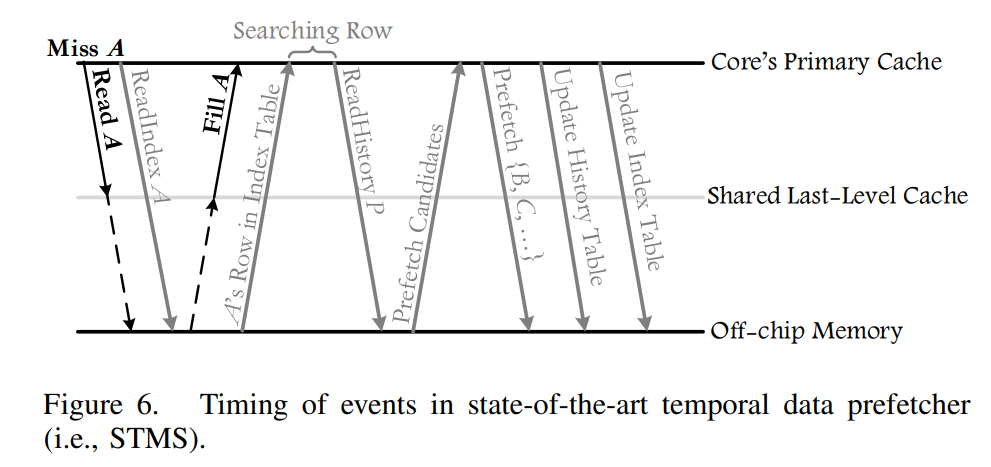
- 访问速度慢,metadata traffic很大。History Table和Index Table很大,都是放在memory里面的。
- metadata没有办法cache, 因为他是以FIFO buffer的形式存在的,但是memory访问是随机的
1.2. Domino
STMS通过一个地址来匹配GHB,这样的准确率是不够的。
Domino优化了STMS。Domino可以使用一个或两个地址匹配GHB。
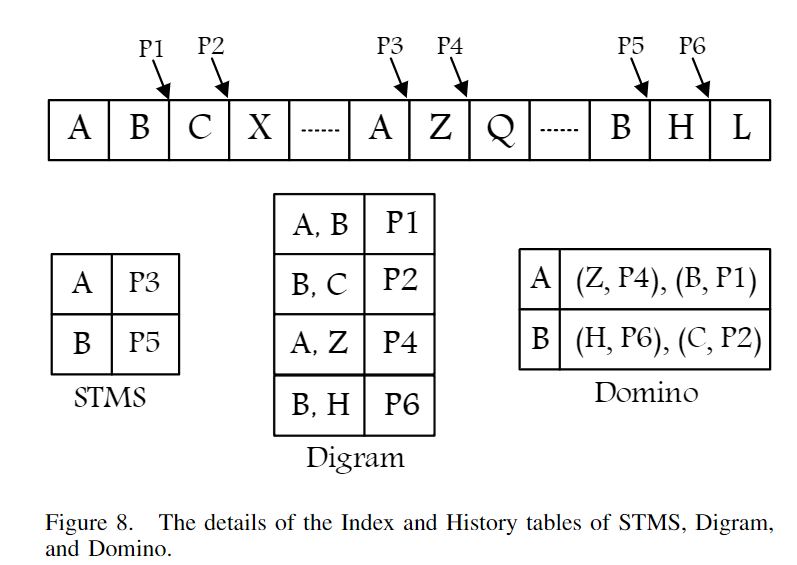
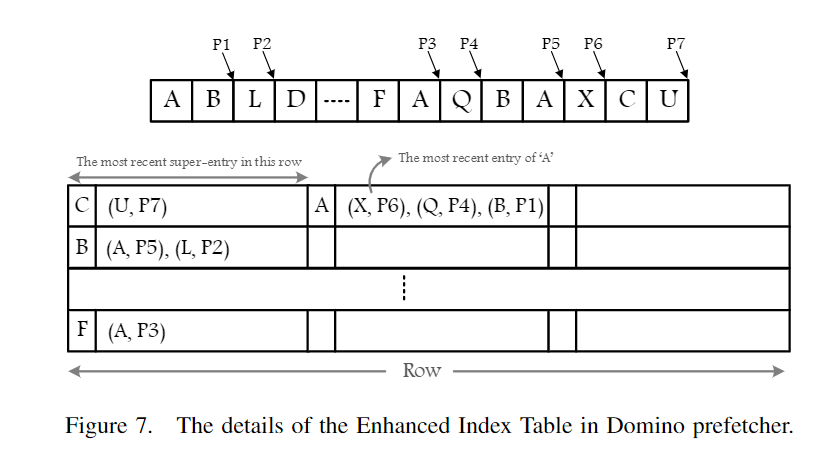
如下图所示,上方A,B,C,X是一个global access stream,下方是三个GHB-based prefetcher的index table的结构。
- STMS: 一个miss addr匹配GHB
- Diagram: 连续两个miss addr匹配GHB
- Domino: 二级match。第一级用第一个miss addr,第二级看第二个访问地址,匹配GHB
a. Structure
-
History Table (HT): a circular FIFO buffer --> in DRAM
-
Enhanced Index Table (EIT): set-associative structure, stores a pointer for every observed miss addr to its last occurrence in the History Table --> in DRAM
-
Other Storage elements next to each core
- a buffer to record the sequence of triggering events named LogMiss (存放两个miss entry)
- a buffer to keep the prefetched cache blocks named Prefetch Buffer
- a buffer that holds the sequence of addresses of an active stream named PointBuf (存放HT的一段stream)
- a buffer named FetchBuf (存放EIT的row)
b. Process
触发prefetch的triggering event有
- cache misses
- prefetch hits
b.i. Recording
- Triggering
- triggering event发生,记录其addr到LogMiss (LogMiss has the capacity of two cache blocks.)
- Updating HT
- 当LogMiss有数据的时候,Domino会将其append到HT,并且概率性的更新EIT (不是每一次都会更新EIT的)
- Updating EIT
- N个triggering events(比如8)写到HT之后,对应的EIT row会被取到FetchBuf(如果不存在,则根据LRU policy allocate)。
- 在EIT super entry中,根据第二个miss addr进行查询,更新指向HT的指针(如果不存在,则在super entry中根据LRU进行替换)
- 最后更新entry内部的LRU和所有entry的LRU信息。最后写回memory
b.ii. Replaying (replay first, record second)
PointBuf存放了Domino要prefetch的address stream(从HT获取)。
如果遇到了triggering event prefetch hit, Domino会继续prefetch PointBuf中的addr
如果遇到了triggering event cache miss, Domino认为PointBuf中的序列需要更新,就会find a new stream。
Find a New Stream:
- Domino用当前triggering evetn的addr去获取EIT row。如果获取到了EIT row, 就会根据其super entry中的most recent entry去发起prefetch请求。如果没有匹配的,就什么都不做
- 下一个triggering event来时,Domino查询super entry里是否匹配第二个addr。
- 如果没有match,Domino会放弃这个stream,并且将当前的triggering event作为首个addr再去EIT中寻找匹配的EIT row。
- 如果match, Domino根据EIT提供的指针去HT中获取addr stream读到PointBuf中。然后开始发起prefetch请求
2. Irregular Stream Buffer
2.1. Simple ISB
- MICRO'13 Linearizing Irregular Memory Accesses for Improved Correlated Prefetching
- slides
- Gem5 ISB codes
- ISB Code
STMS和Domino使用的都是global access stream。而ISB这篇文章认为用PC-localized stream(每一条load指令的miss stream)更好。
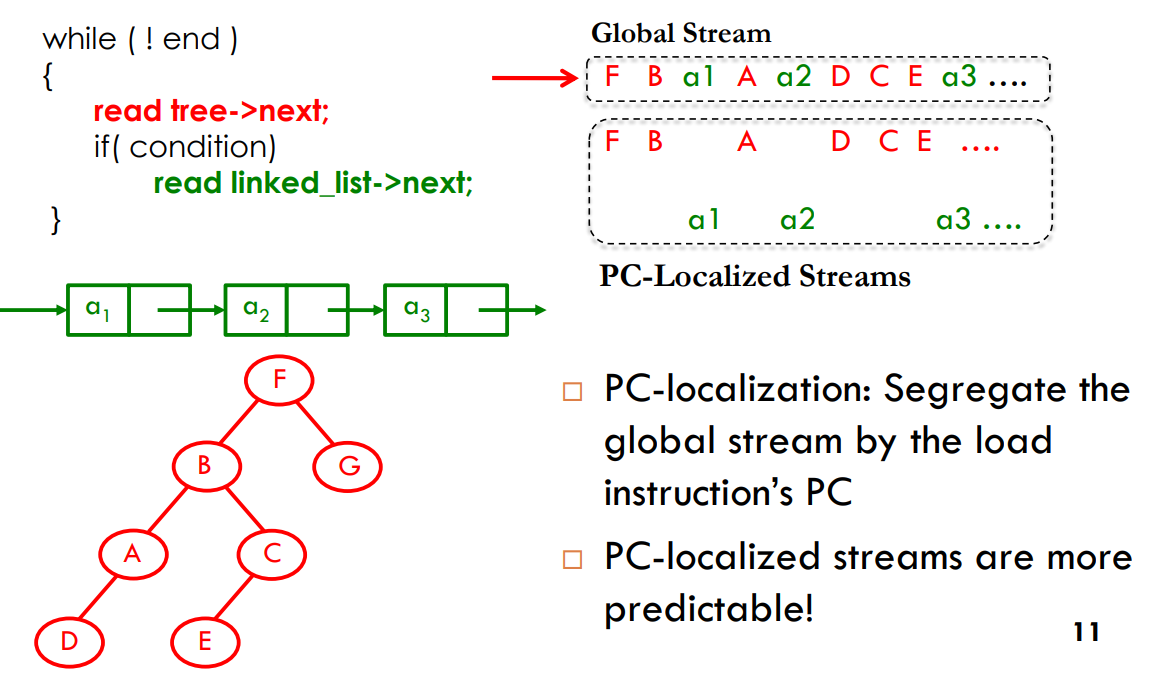
但是基于GHB的prefetcher是很难实现pc-localization的。如下图所示,用PC去index stream, pc-localized stream内部通过linked list来串联。
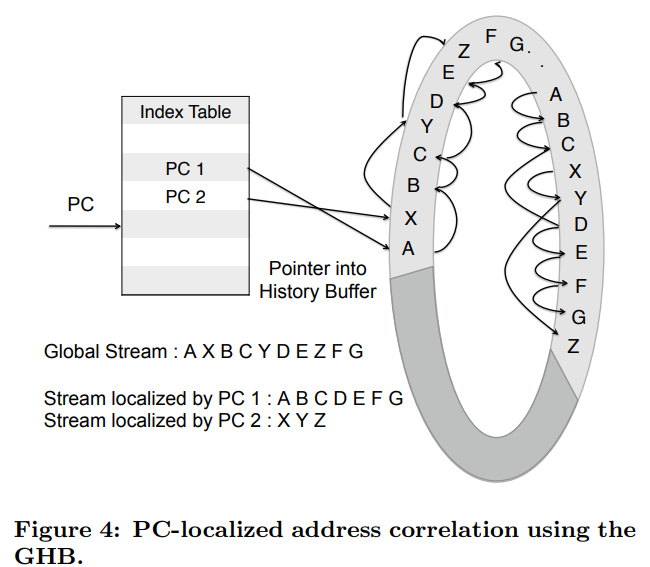
而ISB很好的结合了Address correlation和PC-localization。并且支持metadata的prefetch。
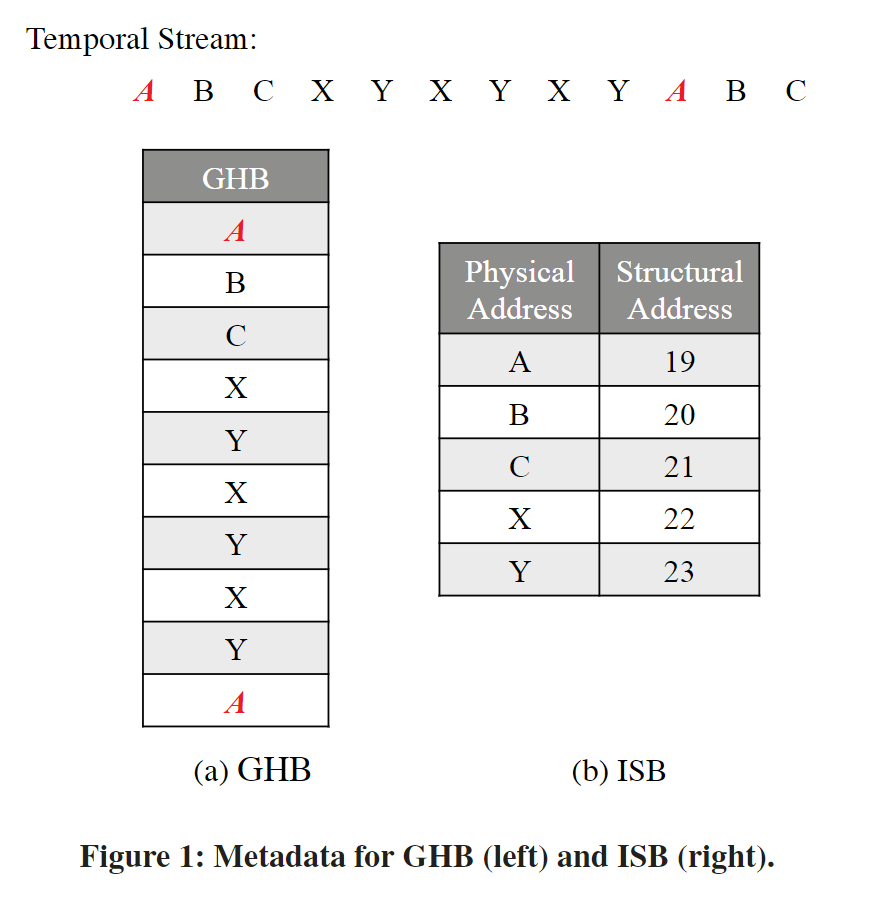
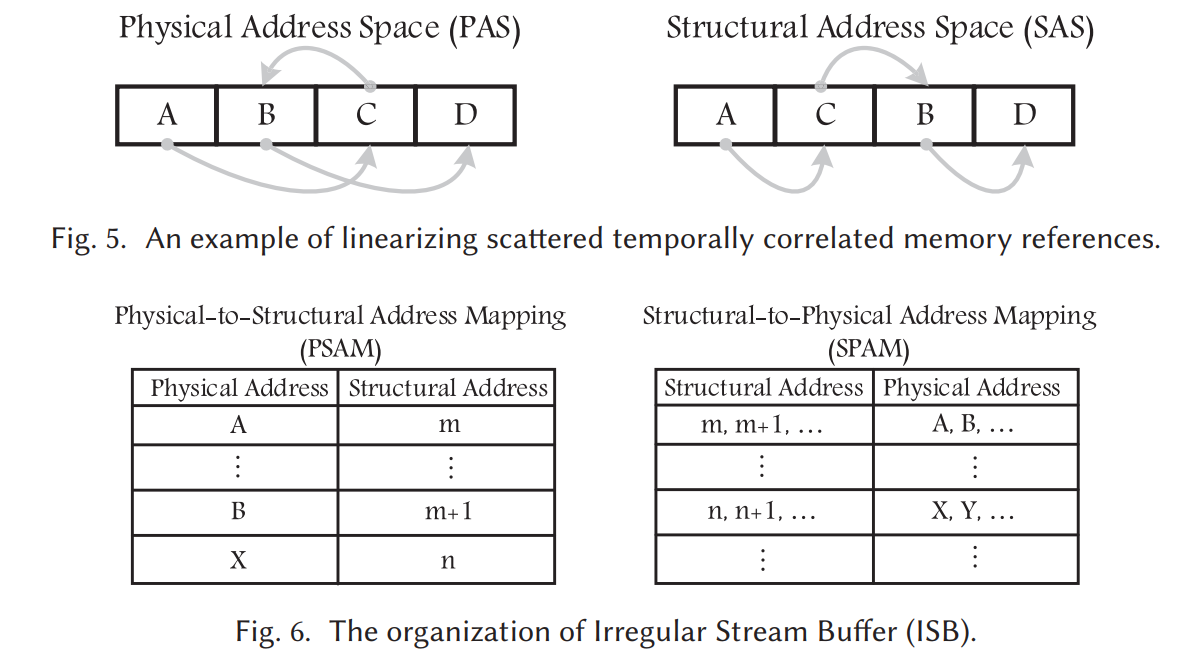
ISB将correlated physical addr映射到一个新的地址空间:structural address space。Temporal stream在structural address space中地址分配的地址是连续的,能够通过Next line prefetcher进行Prefetch
a. Components
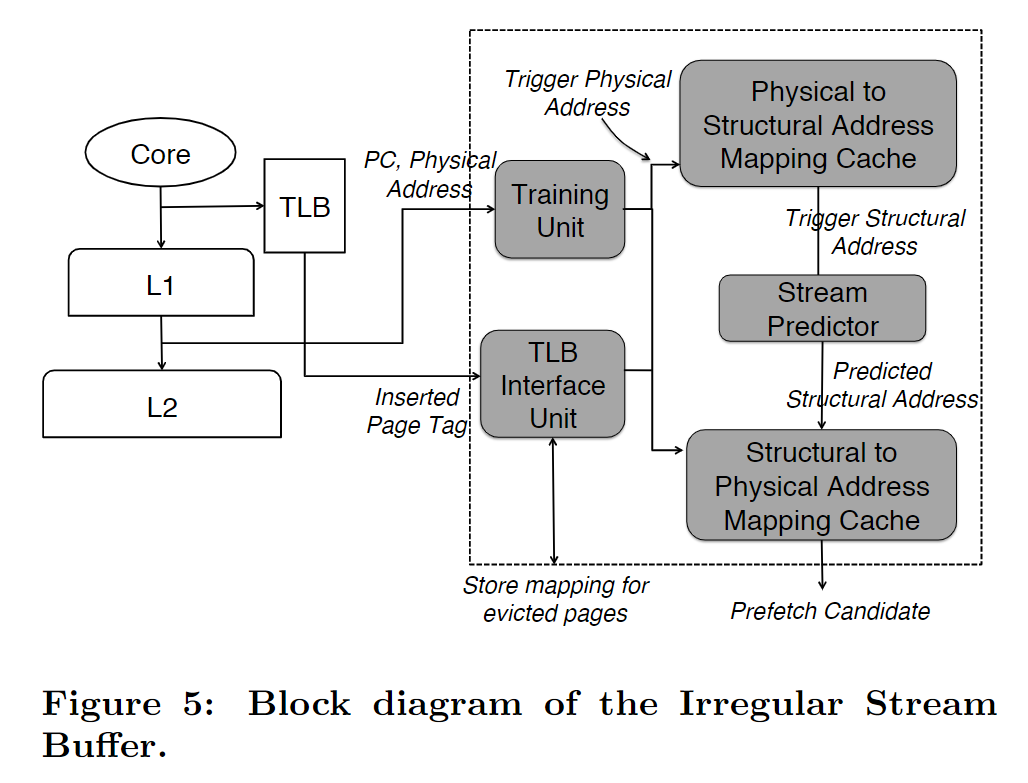
a.i. Training Unit: Segregates global stream by PC and assigns structural addresses
Input
- load PC
- load address
这个模块维护PC-localized stream中每个PC最后访问的地址 last observed addr。
当一个Input来的时候,通过Input PC匹配stream, 然后为Input Addr分配一个在last observed addr后的structural address。然后更新last observed addr为当前Input Addr。
a.ii. Address Mapping Caches (AMCs)
- The Physical-to-Structural AMC (PS-AMC) stores the mapping from the physical address space to the structural address space; it is indexed by physical addresses.
- The Structural-to-Physical AMC (SP-AMC) stores the inverse mapping as the PS-AMC and is indexed by structural addresses.
a.iii. Stream Predictor
类似stream buffer
a.vi. TLB Sync
ISB的cache缓存TLB resident page中的cache line的信息,并且会和TLB miss协同工作(page被evict了,则cache中的mapping被写回,page被load了,则cache会load mapping)。
b. Process
ISB’s three key functions: training, prediction, and TLB eviction
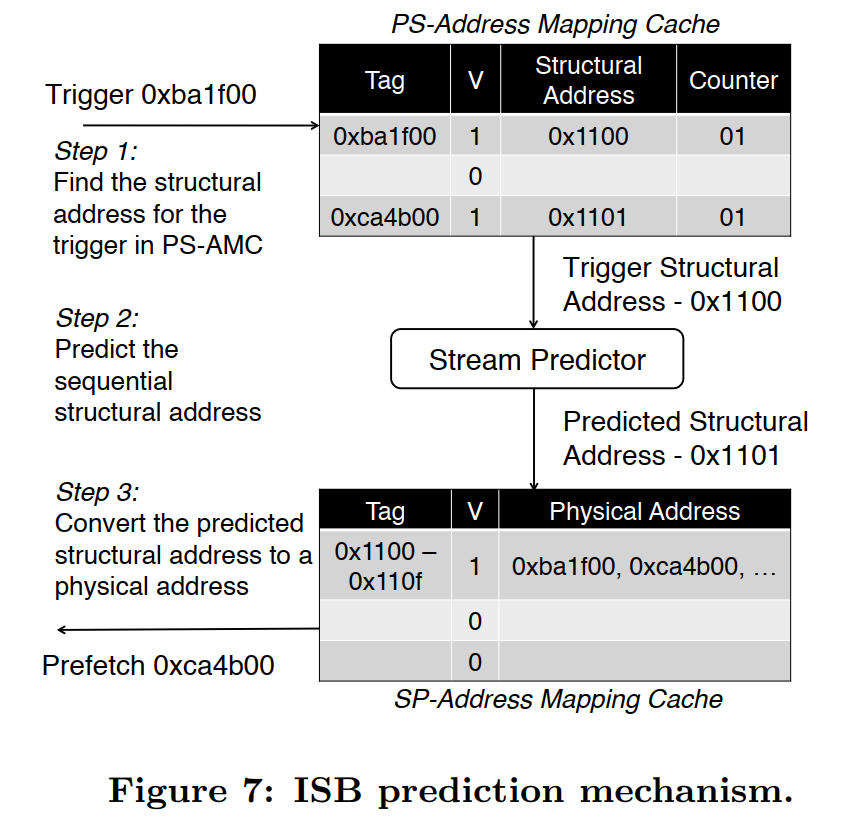
b.i. Training
The training process assigns consecutive structural addresses to the correlated physical addresses that are observed by the training unit.
Example:
the Training Unit’s last observed address is 0xba1f00, whose structural address is 0x1100.
When the Training Unit receives the physical address 0xca4b00 in the same localized stream, it performs three steps.
- It assigns 0xca4b00 the structural address following 0xba1f00’s structural address, namely 0x1101.
- It updates the PS-AMC entry indexed by physical address 0xca4b00, and it updates the SP-AMC entry indexed by structural address 0x1101.
- It changes the last observed address in the Training Unit to 0xca4b00.

b.ii. Prediction
Each L2 cache access becomes a trigger address for the prefetcher, causing the PS-AMC to retrieve the trigger address’ structural address.
b.iii. TLB evictions
During a TLB eviction, the ISB writes to DRAM any modified mappings for the evicted page, and it fetches from DRAM the structural mapping for the incoming page.
c. Overhead
c.i. Traffic
8.4% memory traffic overhead due to meta-data accesses
c.ii. Storage
- For the hybrid experiments, we use an 8 KB ISB, because a 32 KB ISB provides only a small speedup improvement.
- For the non-hybrid experiments, we use a 32 KB ISB, which contains a 16 KB direct-mapped PS-AMC with 32-byte cache lines, and which uses an 8-way set-associative SP-AMC with 32-byte cache lines. (map all pages in a 128 entry data TLB)
- Offchip: It suffices to reserve for the ISB 8 MB of off-chip storage. By contrast, the GHB-based prefetchers that we simulate require up to 128 MB of off-chip storage for the same workloads.
2.2. Optimized MISB
MISB在ISB的基础上改进了metadata的管理方式。MISB引入了metadata prefetching
a. Components
- The Training Unit finds correlated addresses within a PC-localized stream and assigns them consecutive structural addresses.
- On-chip mappings are stored in the PS and the SP caches, and on eviction, they are written to the corresponding off-chip PS and SP tables.
- The Bloom filter tracks valid PS mappings and filters invalid off-chip requests for PS mappings.
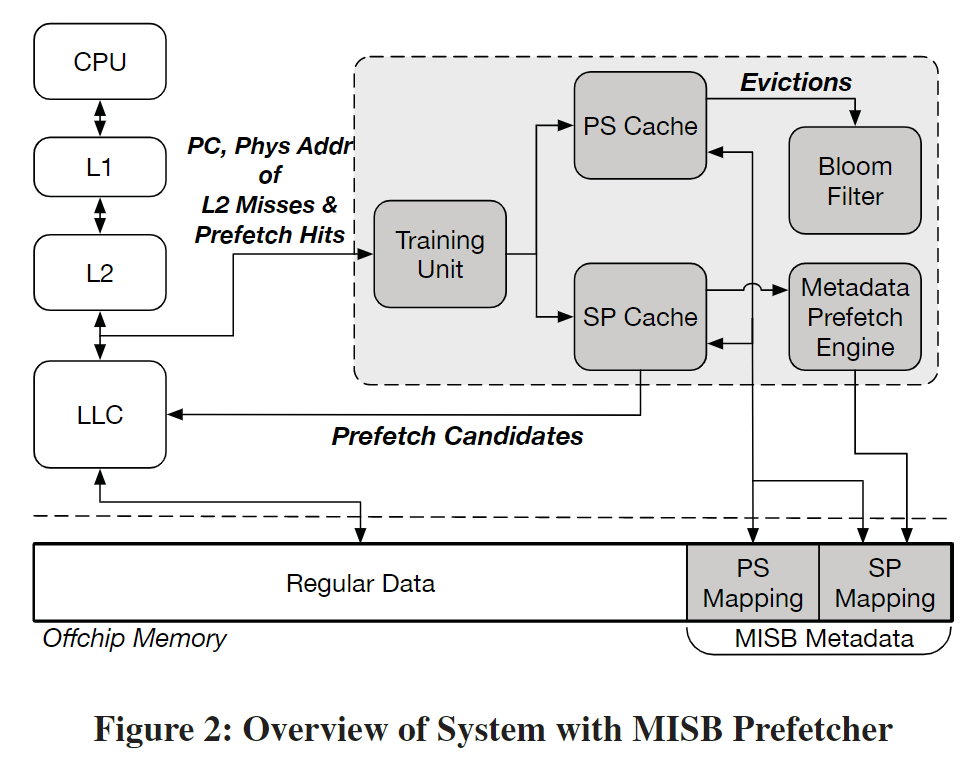
a.i. Metadata Cache
- PS cache: physical -> structural
- SP cache: structural -> physical
Each logical metadata cache line in MISB's PS and SP caches holds one mapping, and on an eviction, the least recently used mapping is evicted.
a.ii. Metadata Prefetching
On PS and SP metadata cache misses, MISB gets prefetching benefits from fetching a metadata cache line with 8 mappings.
a.iii. Metadata Filtering
Many PS load requests are to physical addresses for which MISB has no mapping since they have never been seen before.
To filter these requests, MISB uses a Bloom Filter.
In particular, when a new PS mapping is written to off-chip storage, the mapping is added to a Bloom filter. Future PS misses are sent to memory only if the physical address is found in the Bloom filter.
b. Process
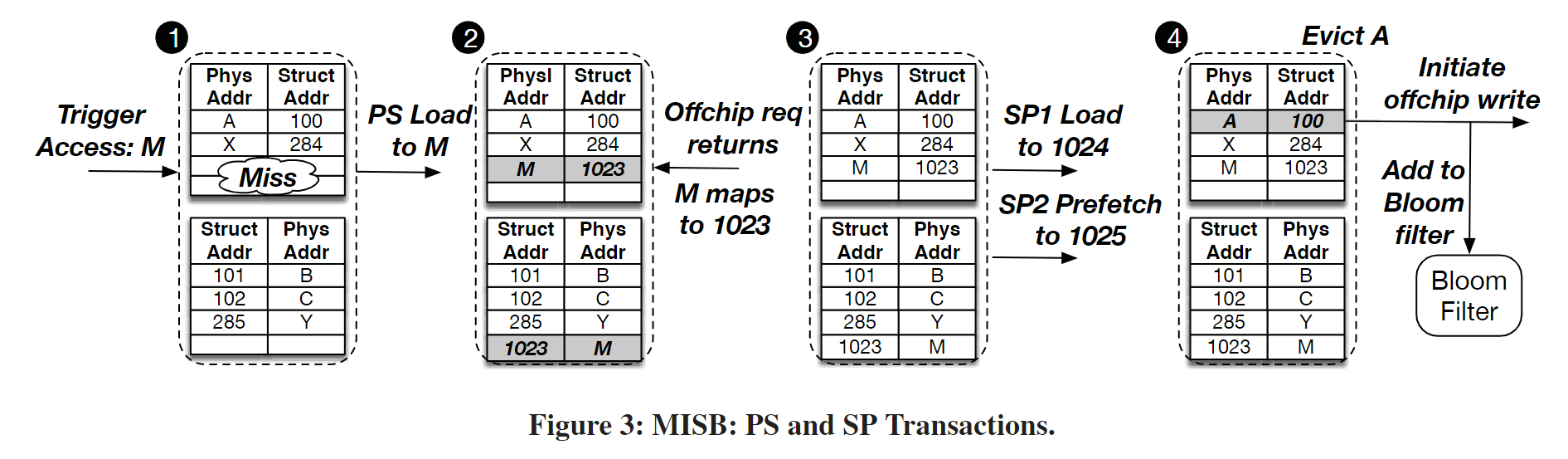
c. Overhead
c.i. Traffic
- single-core workloads
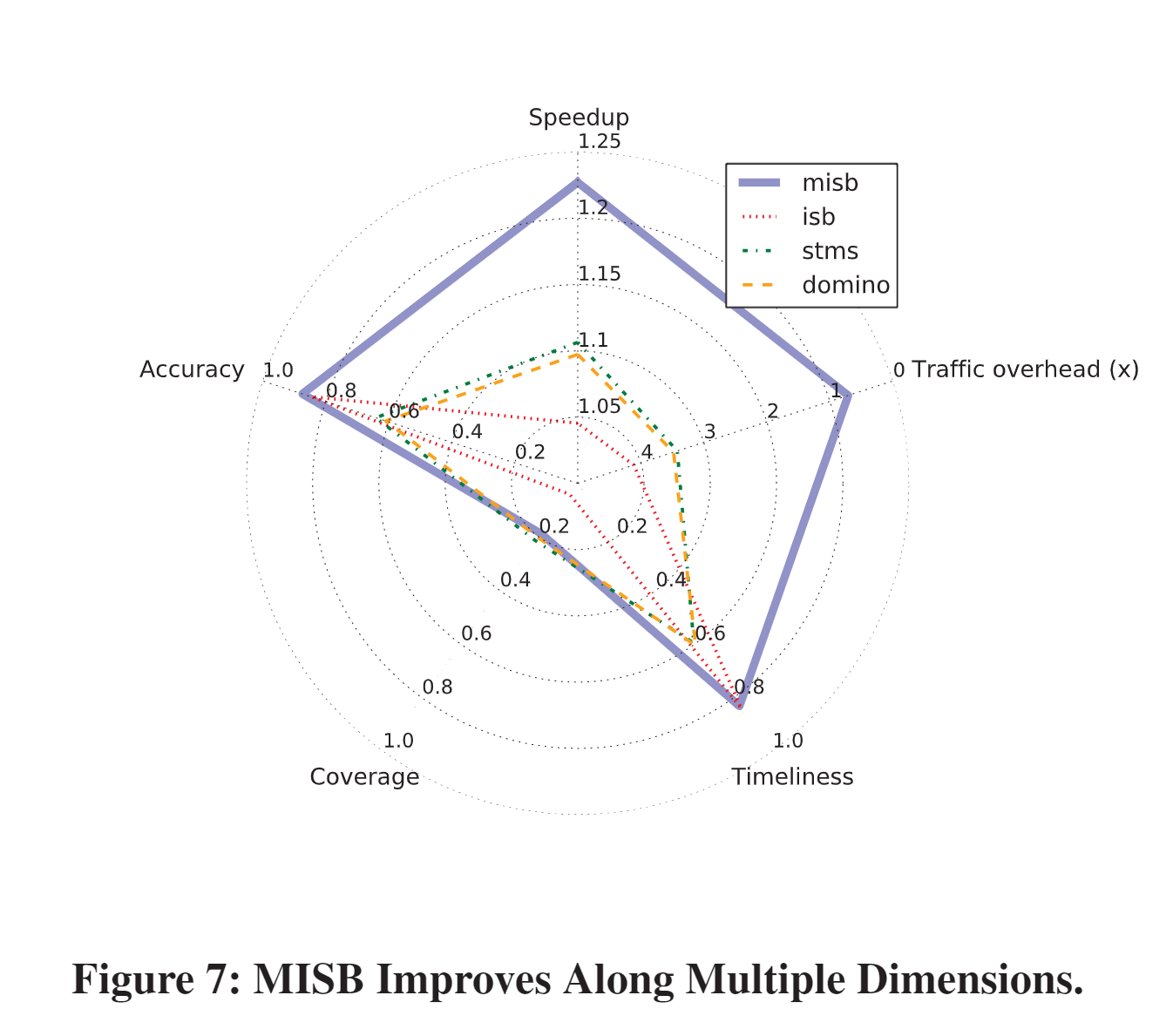
- MISB also significantly reduces off-chip traffic; for SPEC, MISB's traffic overhead of 70% is roughly one fifth of STMS's (342%) and one sixth of ISB's (411%)
c.ii. Storage
32KB for the on-chip metadata cache and 17KB for the Bloom filter (Bloom Filter这么大吗)
3. Category 3: Table-Based
3.1. Markov Prefetcher
omit
3.2. Triage
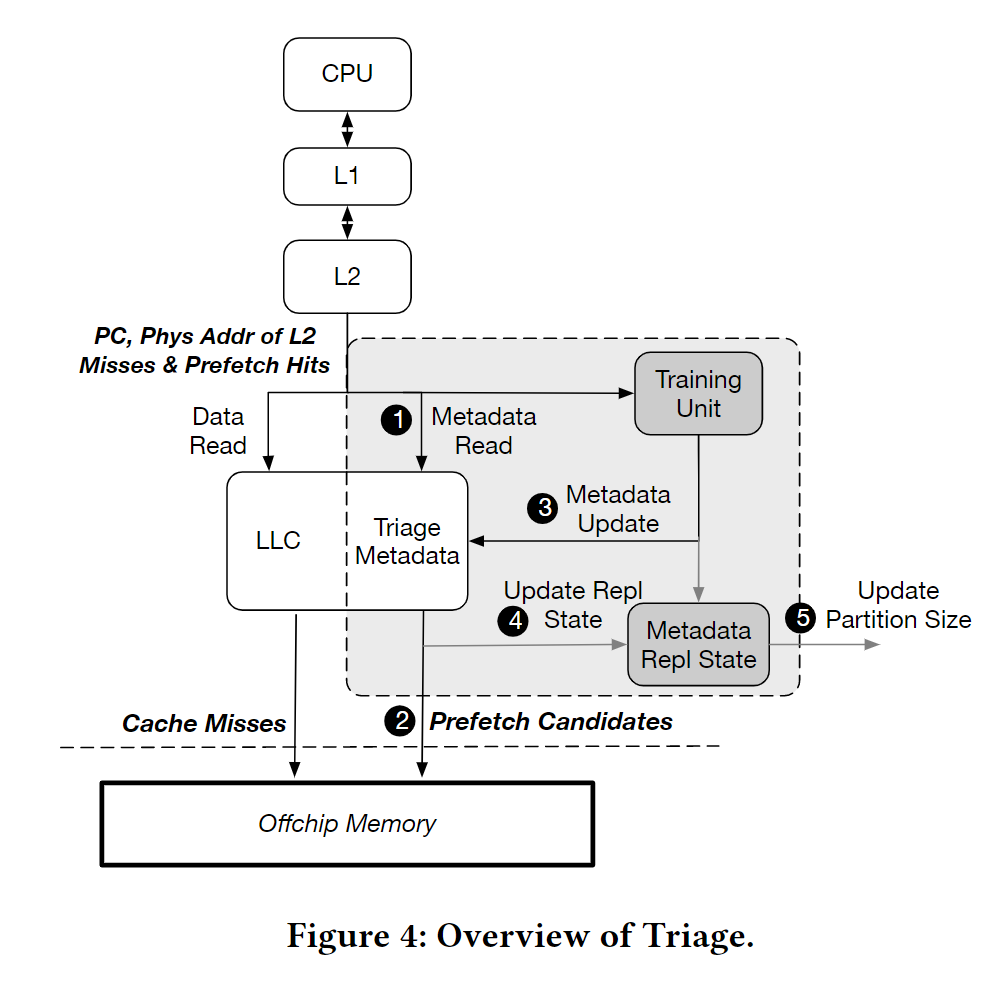
Triage提出了一个metadata完全on-chip的temporal prefetcher(将metadata存储到LLC)。Triage认为绝大部分性能的提升来自一小部分metadata。
a. Components
a.i. Training Unit
和ISB中的training unit类似。
维护PC-localized stream中每个PC最后访问的地址 last observed addr。
a.ii. Metadata Store
在LLC中划分一块空间作为metadata store, 存储metadata。
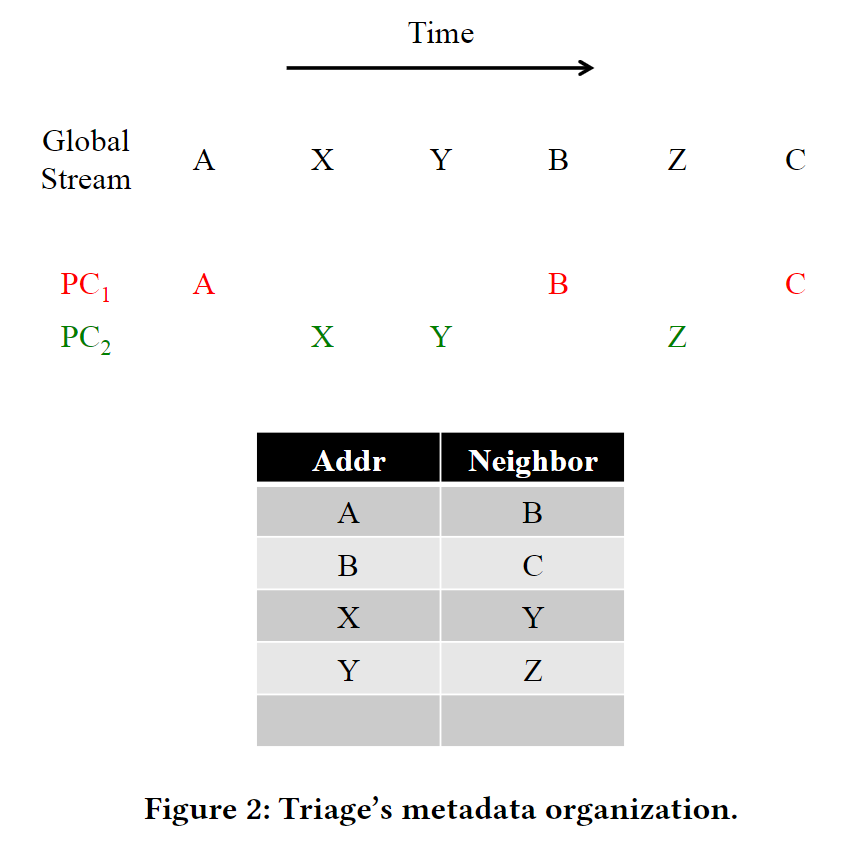
Triage以table形式存储address correlation。
b. Process
b.i. Training
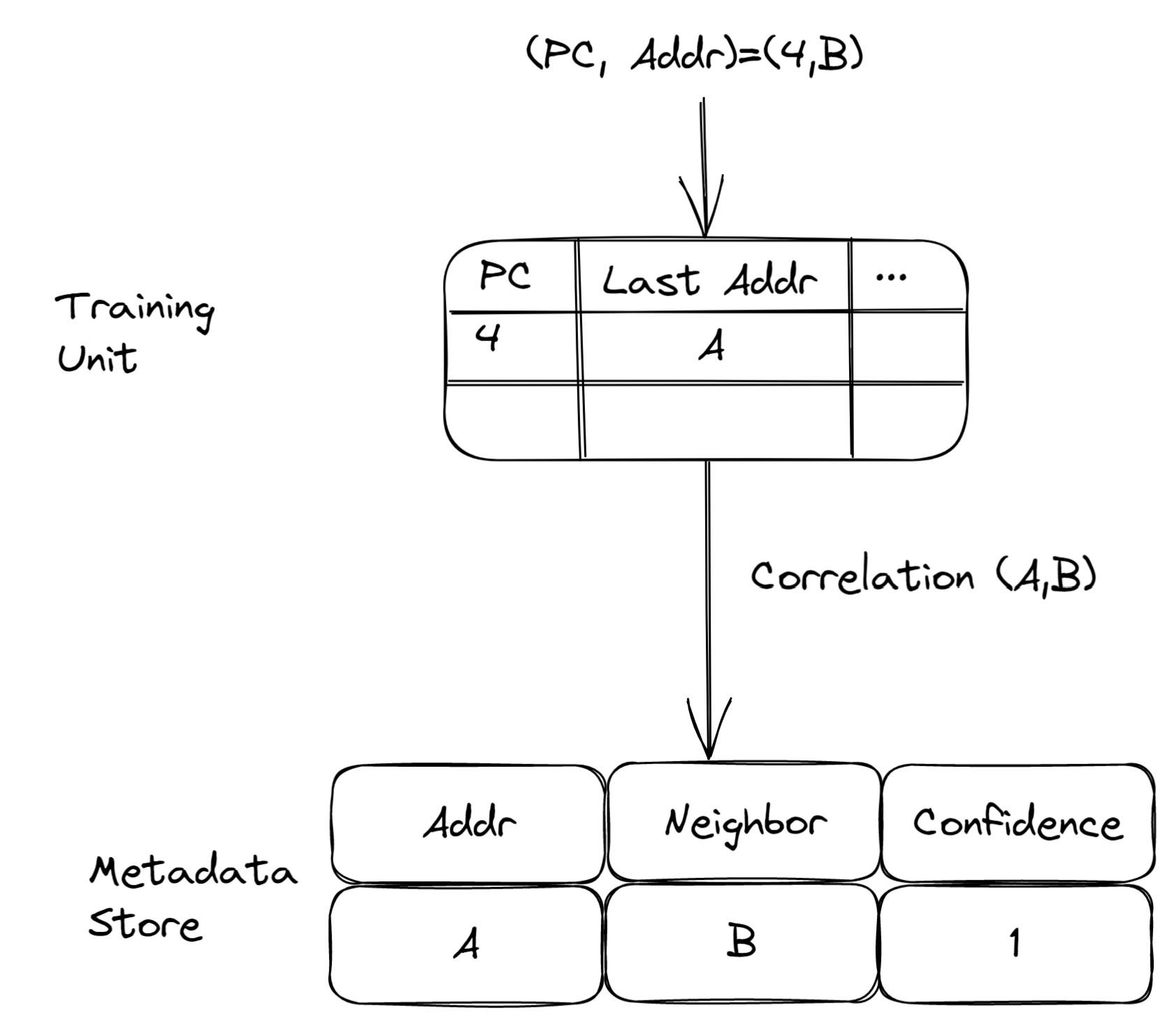
下面是一个training的例子。
假设training unit中pc为4的stream的last observed addr是A。Input了(PC, Addr)=(4,B), 那么training unit认为A和B存在correlation, 并将这个correlation发送给Triage的metadata store
b.ii. Prediction
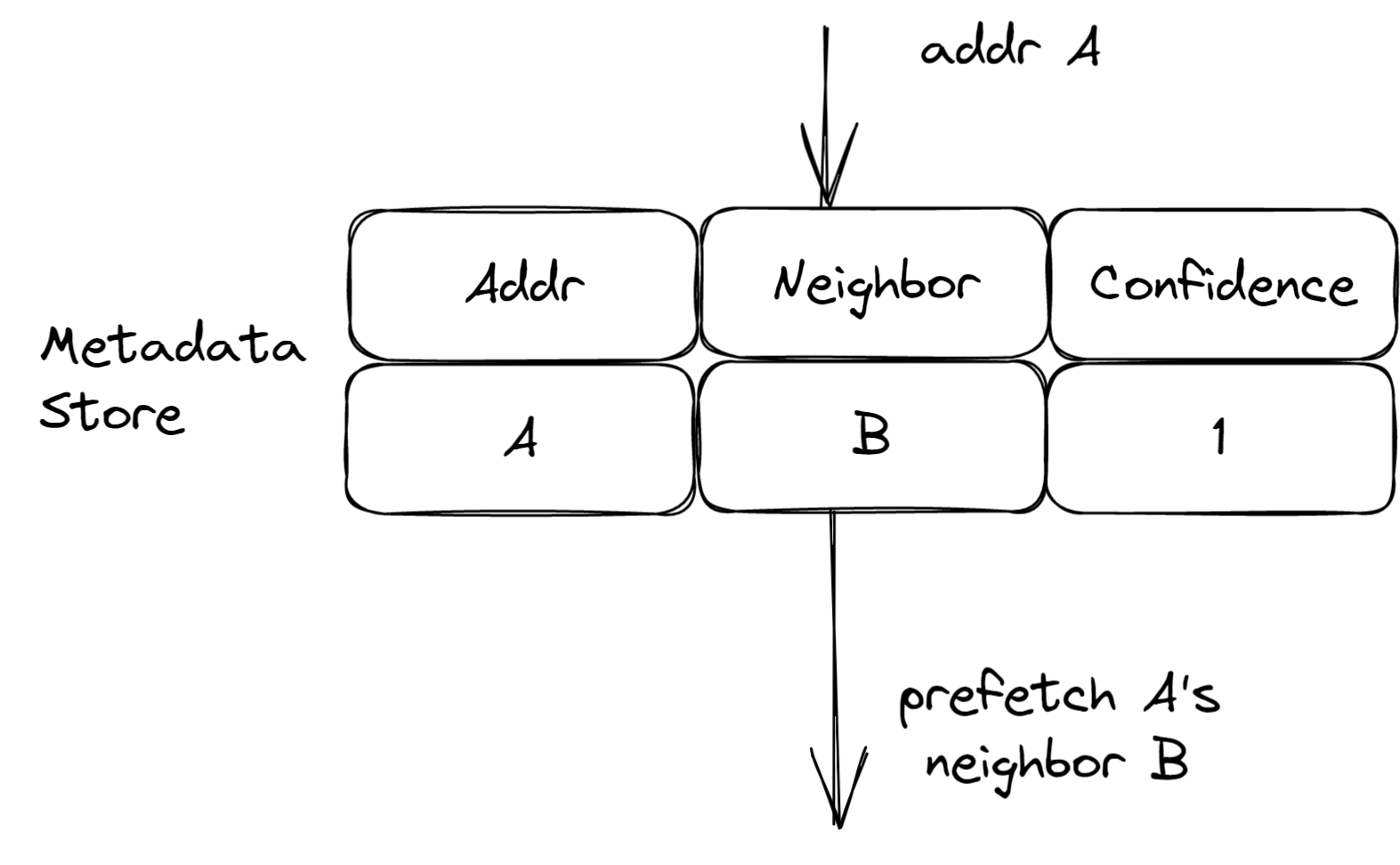
当一个地址A来的时候,Triage搜索metadata store发现匹配项(A,B), Triage对B发起prefetch request
b.iii. Metadata Replacement
Hawkeye replacement policy
b.vi. Metadata Partition Updates
每隔多少次metadata access, 重新做一次LLC的way partition,动态扩缩metadata store占用的LLC的大小。
如果triage要扩张,那么dirty cache line被flush并且标记为invalid供triage使用
如果triage要缩小,那么triage占用的位置被标记为invalid供llc使用
c. Overhead
c.i. Storage
Occupy LLC 512KB/1MB/Dynamic allocation